
Every mainframe DB2 shop should investigate reducing their costs by offloading workload to an IDAA appliance. By following the steps in this blog series, you can understand how to evaluate and justify an IDAA appliance for your existing environment workloads at no cost. After investigating my daily SQL workload, I discovered millions of mainframe CPU MIPS that could be saved by using an IDAA appliance, so begin your IDAA justification at no cost today.
Hopefully everyone has had a chance to read the first three parts of this series. In the first part I talked about the setup steps for getting an IDAA Virtual Server configured and deployed within your environment. In the second part I walked through the steps to quickly and easily define an IDAA Virtual Server and a “production-like” environment for your investigation and justification activities. In Part 3 I explained how to capture and examine your different SQL workloads for the right SQL to use to justify an IDAA environment.
In this Part 4 blog of “Justifying your IBM DB2 Analytics Accelerator IDAA,” I will explain how to interpret the Data Studio Analytics Accelerator evaluation results.
Reading the analysis of your SQL against your IDAA environment
- When starting out, choose all the Data Studio analysis options for each group of SQL. The Data-Studio-produced reports contain sections for RUNSTATs recommendations, index recommendations, query advisor, access path advisor, and Analytics Accelerator Advisor information. Look over all the report sections and evaluate whether there are any glaring problems. Sometimes problems occur when updating the statistics for the “DEFINE NO” table, and index definitions make these errors visible. Also, verify that if there are any test-versus-production, DB2-system-CPU model differences that are negatively influencing your analysis dramatically.
- Next, go into Accelerator Advisor information section and see how many of your SQL statements qualified for the IDAA appliance. In my first set of Analytics Acceleration analysis, the summary report showed that 79 of the 89 SQL statements that I was evaluating in this SQL group were able to utilize the IDAA Virtual Server environment. It also showed that 10 statements could not be offloaded to the IDDA appliance.

- The research to determine why those 10 SQL statements were not qualifying for the IDAA appliance was done through Data Studio and DB2 EXPLAIN tables. First, look at the Data Studio Analysis report The main results of your SQL statements in Data Studio show the eligible and ineligible IDAA statements. Look through the ineligible statements and determine if any of the SQL statements are INSERT/UPDATE/DELETE ambiguous, have unique SQL functions, XMLPARSEing, or special CCSID encoding. Sometimes the IDAA Virtual Server environment does not propagate all your required tables, so retry your using both the IDAA Virtual Server and Analytics Modeling features within the analysis where it consistently shows SQL that is eligible or ineligible. Then research ineligible SQL one step further through the DB2 EXPLAIN tables.

- The DB2 EXPLAIN table and DSN_QUERYINFO_TABLE have more details on the ineligible SQL condition. I like to query this DSN_QUERYINFO_TABLE table through QMF because it has many columns and these extra columns are easily omitted through the QMF Form. When querying the table also look to limit your query with the last date/time of your Analytics Acceleration analysis if possible.
SELECT *
FROM BEULKE.DSN_QUERYINFO_TABLE
WHERE DATE(EXPLAIN_TIME) = ‘2016-08-23‘
ORDER BY QINAME2 DESC, QUERYNO
WITH UR; - You can then retrieve the EXPLAIN output of the IDAA Accelerator analysis using SQL and look at the important columns in the DSN_QUERYINFO_TABLE. The most important columns are REASON_CODE and the QI_DATA columns. These DB2 EXPLAIN table columns contain the root cause problem code that is detailed in the SQL REFERENCE Manual, PLAN Information section, and then in the DB2 EXPLAIN table DSN_QUERYINFO_TABLE.
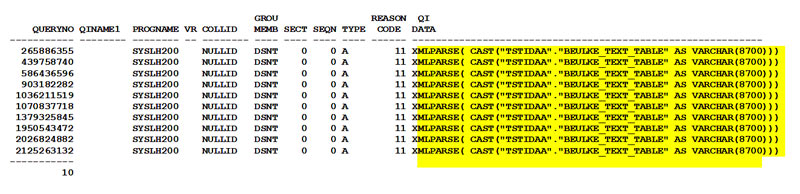
- Looking within the DB2 EXPLAIN table DSN_QUERYINFO_TABLE, the REASON CODE and QI_DATA columns show the key to understanding why the SQL did not qualify for the IDAA appliance. In my situation shown above the REASON_CODE =11 and the data in the QI_DATA column show the XMLPARSE SQL WHERE clause statement is not IDAA eligible as highlighted above. XMLPARSE and some other DB2 functions or WHERE Clause type searches can not be done through the IDAA Analytics engine. This is very disappointing but not shocking since the XMLPARSE clause can be rewritten to be the substring SQL clause (SUBSTR) and position clause (POSSTR). There are many specialized DB2 SQL Functions and IDAA is enabling more functions in every new release.

- By rewriting the SQL with the SUBSTR and POSSTR functions instead of the XMLPARSE statements, these statements can be accepted by IDAA. The SUBSTR and POSSTR statement clauses were easily substituted within the SELECT portion, the WHERE clause join criteria and within the GROUP BY portions of the SQL statements.
For example:SELECT COUNT(*)
FROM BIG_TABLE_1 AS NBR1_TBL
JOIN BIG_TABLE_NBR2 AS NBR2_TBL
ON NBR2_TBL.TABLE_COLUMN_KEY= NBR1_TBL.TABLE_COLUMN_KEY
JOIN XMLTABLE(‘$NBR2_TBLXML/*: MyXMLNodeName’
PASSING XMLPARSE (NBR2_TBL.VARCHAR_XML_TABLE_COLUMN_NAME) AS “NBR2_TBLXML”
COLUMNS ExamplesXMLParseNODE smallint
PATH ‘//*: ExamplesXMLParseNODE’) XMLVALUE
ON NBR2_TBL.VARCHAR_XML_TABLE_COLUMN_NAME IS NOT NULL
AND XMLVALUE. ExamplesXMLParseNODE NOT IN (30,35);Retrieves the same data with the SQL SUBSTR and POSSTR example below:
SELECT COUNT(*)
FROM BIG_TABLE_1 AS NBR1_TBL
JOIN BIG_TABLE_NBR2 AS NBR2_TBL
ON NBR2_TBL.TABLE_COLUMN_KEY= NBR1_TBL.TABLE_COLUMN_KEY
–JOIN XMLTABLE(‘$NBR2_TBLXML/*: MyXMLNodeName’
— PASSING XMLPARSE (NBR2_TBL.VARCHAR_XML_TABLE_COLUMN_NAME) AS “NBR2_TBLXML”
— COLUMNS ExamplesXMLParseNODE smallint
— PATH ‘//*: ExamplesXMLParseNODE’) XMLVALUE
–ON NBR2_TBL.VARCHAR_XML_TABLE_COLUMN_NAME IS NOT NULL
–AND XMLVALUE. ExamplesXMLParseNODE NOT IN (29,35)
WHERE VARCHAR_XML_TABLE_COLUMN_NAME IS NOT NULL
AND
(CASE WHEN VARCHAR_XML_TABLE_COLUMN_NAME IS NOT NULL
AND VARCHAR_XML_TABLE_COLUMN_NAME LIKE ‘% ExamplesXMLParseNODE%’
AND SMALLINT(
SUBSTR(VARCHAR_XML_TABLE_COLUMN_NAME,
(POSSTR(VARCHAR_XML_TABLE_COLUMN_NAME, ‘< ExamplesXMLParseNODE>’) + 23),
(POSSTR(VARCHAR_XML_TABLE_COLUMN_NAME, ‘</ ExamplesXMLParseNODE>’) –
POSSTR(VARCHAR_XML_TABLE_COLUMN_NAME, ‘< ExamplesXMLParseNODE>’) – 23 )
)) NOT IN (30,35)
THEN ‘OK’
ELSE ‘IT WAS NULL’
END) = ‘OK’
;The SQL now qualifies for using the IDAA Accelerator environment and saves even more CPU on a daily basis. Not all SQL situations are rewritable but with the XMLPARSE and the SUBSTR and POSSTR clauses, the SQL is easily rewritten and resolved for using the IDAA Accelerator appliance.

IDAA can have a huge impact on your overall processing. By avoiding the CPU demands of these daily SQL statements, the mainframe can offload this workload to IDAA and save a tremendous amount of CPU against its Master Licensing Charges. Also since the IDAA Accelerator Appliance can process much faster than regular DB2, the time to answers is dramatically improved. Next time we will go through the speed aspects of using an IDAA Analytics Accelerator and detail some of the performance aspects and other CPU and storage savings opportunities.
Are you planning on going to the World of Watson conference in Las Vegas at the end of October? Come to my presentation “Justified Big Data Performance: Transform your business with IBM Analytics Accelerator – IDAA,” Tuesday 25-Oct, 3:00 PM-3:45 PM in the Mandalay Bay – Jasmine B Session DMT-2041. #ibmwow

If you are not going to the IBM World of Watson conference you can hear my educational session “Justified Big Data Performance transforms your business with IBM Analytics Accelerator – IDAA” through a replay of my DB2NightShow from October 14th. Go to the DB2 Night Show website or click on this link.
Links to other parts:
Process to Justify an IBM DB2 Analytics Accelerator (IDAA) Part 1
Process to Justify an IBM DB2 Analytics Accelerator (IDAA) Part 2
Process to Justify an IBM DB2 Analytics Accelerator (IDAA) Part 3
Dave Beulke is a system strategist, application architect, and performance expert specializing in Big Data, data warehouses, and high performance internet business solutions. He is an IBM Gold Consultant, Information Champion, President of DAMA-NCR, former President of International DB2 User Group, and frequent speaker at national and international conferences. His architectures, designs, and performance tuning techniques help organization better leverage their information assets, saving millions in processing costs.



Leave a Reply